Buenas,
Tengo datos de las llegadas de clientes a un call center distribuidos por horas y me gustaría saber si existe algún test en R que me marque homogeneidad en los datos.
Gracias,
Un saludo
Buenas,
Tengo datos de las llegadas de clientes a un call center distribuidos por horas y me gustaría saber si existe algún test en R que me marque homogeneidad en los datos.
Gracias,
Un saludo
Alguien me puede explicar, ¿por qué la prueba shapiro.test opera solo con muestra mayores que 3 y menores que 5000?
Buenos dias,
Tengo un excel con 3000 observaciones y 9 variables del que quiero guardar en un vector el valor "interarrivals" cuando la variable "time" este entre las 7 y las 9 de la mañana, adjunto pantallazo de la estructura de la tabla
El codigo que habia hecho era
library(readxl)
M1 <- read_excel("M1.xlsx",
col_types = c("numeric", "numeric", "numeric",
"numeric", "numeric", "numeric",
"numeric", "numeric", "date"))
a<-c()
tiempo_llegadas<-M1[1:3694,9]
tiempo_entre_llegadas<-M1[1:3694,8]
for (i in 1:3694) {
if (7<=tiempo_llegadas[i,1]<9){a<-c(a,tiempo_entre_llegadas[i,1])}
}
Pero me da error, ¿Podeis echarme una mano?
Gracias,
estadisticas_descriptivas<-function(x){
promedio<-mean(x)
maximo<-max(x)
minimo<-min(x)
desviacion<-sd(x)
if (is.numeric(x)==T){paste("El valor promedio de la variable",x, "es",promedio<-mean(x), "su valor mínimo
es igual a",minimo<-min(x), "su valor máximo es igual a", maximo<-max(x), "y tiene una desviación estándar
de", desviacion<-sd(x))} else {paste("La variable",x, "no es numérica")}
}
Buenos días,
Estoy intentando generar con R Markdown el primer capítulo de una publicación para varios años (2017, 2018 y 2019). Lo que quiero es generar los informes capitulo1-2017.pdf, capitulo1-2018.pdf y capitulo1-2019.pdf.
En la cabecera YAML de mi archivo (capitulo1.Rmd) he puesto el siguiente código:
params:
year:
label: "Año de la publicación"
value: 2018
input: select
choices: [2017, 2018, 2019]
y después, en el mismo archivo (capitulo1.Rmd, he incluido la función render:
```{r include=FALSE}
library(rmarkdown)
render_capitulo = function(year){
rmarkdown::render("capitulo1.Rmd",
output_file = paste0 ('capitulo1-', year)
)
}
```
La cosa es que no me funciona. El informe que me genera se llama capitulo1.pdf.
Muchas gracias de antemano.
Buenas noches, estoy intentado realizar un análisis multivariante por componentes con los datos de mi proyecto de investigación por medio del Software Rwizard, el problema aquí es que al ejecutar el siguiente script:
"data<-read.csv2("C:/Users/Sebastian/Desktop/Trabajos/Tesis/excel resultados tesis/CSV FINALES/Multivariante - copia.csv",header=TRUE,encoding="latin1")
XIII2(data = data , var = c("Semana","Precipitacion","Volumen.Lineal","Volumen.Arboreo") , cat = "Mes" , ellipse = TRUE , VIF = TRUE)"
sale el siguiente mensaje en la consola:
"Error in cor(r, use = pairwise) : 'x' is empty"
Realmente ya no sé como solucionar este inconveniente ya que llevó usando R solo un par de semanas y sé más bien poco de programación del mismo o que procedimientos tener en cuenta cuando hay errores, agradecería alguien que pueda explicarme como debo proceder para poder obtener los datos que necesito.
Pdta: Los datos los tengo guardados en un archivo con extensión .csv
Buen día a todos, hace poco estaba trabajando con modelos de Nowcasting, estos modelos tienen como input muchas series de tiempo. Quiero hacer una estimación del PIB, mi pregunta es sobre el funcionamiento del paquete Nowcasting en R. Este paquete hace uso del filtro de Kalman, como indica la teoría que debería hacerse. También me gustaría saber que hace con las series que no son estacionarias. Yo planeaba estacionalizar todas las series y luego aplicar el nowcasting. Gracias
Hola, tengo un archivo NetCDF (extensión .nc) donde se recogen datos de temperatura y donde la longitud viene de 0 a 360.
Usando la librería "raster" he conseguido representar el Índico y Pacífico. Pero el problema aparece al representar el Atlántico puesto que la longitud a tomar va de 250 a 40 (o lo que es lo mismo, de 250 a 360 y de 0 a 40).
He intentado con varias siguientes síntasis, pero no consigo el resultado deseado.
Me pareció que esta síntesis era la más cuerda, es decir, sumar 40 a 360, pero sólo me plotea hasta 360. Cosa lógica ya que los datos sólo llegan a 360.
plot(variable,col=rainbow(1000),main="Sea Surface Temperature (Atlantic Ocean)",xlab="Longitude",ylab="Latitude",xlim=c(250,400),ylim=c(-90,90),asp=0)
Otra opción que he pensado es crear antes una matriz extrayendo los datos del Atlántico y luego representarla. Pero parece que la función plot no sirve para dibujar estos mapas y con la función image me cambia las unidades de los ejes y voltea el dibujo.
Alguien me podría ayudar de alguna forma?. Ya sea con la síntasis de plot o con otra que me muestre los valores de longitud y latitud sin modificar?.
Hola,tengo el sgte problema. Necesito hacer regresión múltiple en R. El tema es que el resultado sale NA , a la tabla no le faltan datos. Utilice la función is.na para la data.frame, salen todas las variables FALSE en todas las filas,por lo que averigue eso quiere decir que no hay datos NA. Hay 3 columnas que me dan NA a las cuales les hago el is.na a cada una Y dan. FALSE. También opté ppr omitir éstas 3 columnas, e igual sale el p:NA Y r2ajustado: NAN. Probé la función na.omit. el resultado es el mismo. Ayuda por favor
Hola,
he realizado un AFC mediante Lavaan a través del siguiente comando:
modelo4 <- 'Intrinseca =~ M1 + M6 + M11 + M16
Identificada =~ M2 + M7 + M12 + M17
Introyectada =~ M3 + M8 + M13 + M18
Externa =~ M4 + M9 + M14 + M19
Desmotivacion =~ M5 + M10 + M15 + M20
Autonoma =~ Intrinseca + Identificada
Controlada =~ Introyectada + Externa'
fit <- cfa(modelo4, data = datos)
summary(fit, fit.measures = TRUE, standardized=TRUE)
El resultado se muestra en la siguiente figura:
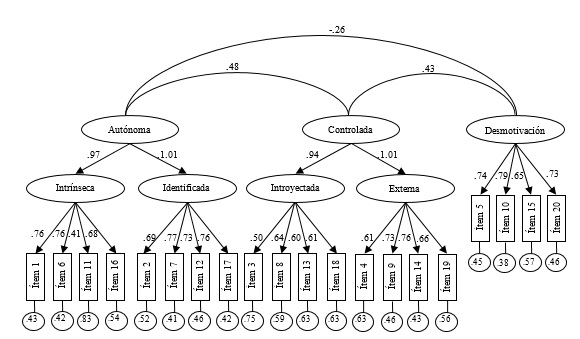
Como se puede apreciar, en dos casos, el peso de regresión es superior a 1, y como conscuencia, tienen una varianza negativa.
¿Cuál puede ser error? y en todo caso, ¿Cómo se podría solventar?
Muchas gracias.