Estoy aprendiendo a manejar R.
Tengo el siguiente ejercicio.
c<-rnorm(100)
luego deseo crear un vector con los valores de las posiciones pares (p) de x y otro con los valores de las posiciones impares (i).
¿Alguien me puede ayudar?
Estoy aprendiendo a manejar R.
Tengo el siguiente ejercicio.
c<-rnorm(100)
luego deseo crear un vector con los valores de las posiciones pares (p) de x y otro con los valores de las posiciones impares (i).
¿Alguien me puede ayudar?
Buenas tardes,
Estoy realizando una prueba para calcula el solapamiento de nicho y uno de los comandos para realizar un PCA en el ejemplo utilizado para explicar la prueba es scores.sp.nat <- suprow(pca.env,nat[which(nat[,11]==1),3:10])$li
Quisiera saber que significa el número 11. pues ya se que significa 3:10.
Si alguien me puede ayudar estaré infinitamente agradecido.
Nota: estoy trabajando con el paquete ecospat.
Gracias
Hola a todos y a todas
Espero que alguien me pueda ayudar.
Voy a hacer un trabajo en el que tengo que establecer la relación entre unas medidas de contaminación y ciertos datos de salud, pero no sé cómo puedo hacerlo con R.
Tengo una tabla con índices de contaminación por días de este estilo:
| 08/12/2015 | NOX | 42 | |
| 08/12/2015 | NI | ||
| 08/12/2015 | AS | ||
| 08/12/2015 | PB | ||
| 08/12/2015 | C7H8 | 4 | 8 |
| 08/12/2015 | BAP | ||
| 08/12/2015 | CD | ||
| 08/12/2015 | C6H6 | 2 | 6 |
| 08/12/2015 | C8H10 | 2 | 4 |
| 08/12/2015 | SO2 | 3 | |
| 08/12/2015 | CO | 0 | 2 |
| 08/12/2015 | NO | 12 | |
| 08/12/2015 | NO2 | 23 | |
| 08/12/2015 | PM10 | ||
| 08/12/2015 | O3 | 40 |
| Fecha | Diagnóstico | Edad | Sexo | Localidad |
| 08/12/15 | Neumonía | 65 | Mujer | Villar |
| 08/12/15 | Dolor abdominal | 32 | Hombre | Villar |
| 08/12/15 | Asma | 35 | Hombre | Villar |
| 08/12/15 | Fractura brazo | 19 | Hombre | Villar |
¿Alguien me puede dar una pista?
Soy totalmente principiante en esto del R
Gracias
Saludos al foro,
Soy nuevo en uso de visualizacion con R. Estoy construyendo un boxplot para dos grupos, uno que dice SI y otro NO. Por defecto R grafica primero la caja del NO, y luego la caja al SI.
Quiero ordenar a mi gusto la impresion en el eje X, de manera tal que aparezca primero si SI y despues el NO.
Agradezco la ayuda, gracias por su atencion.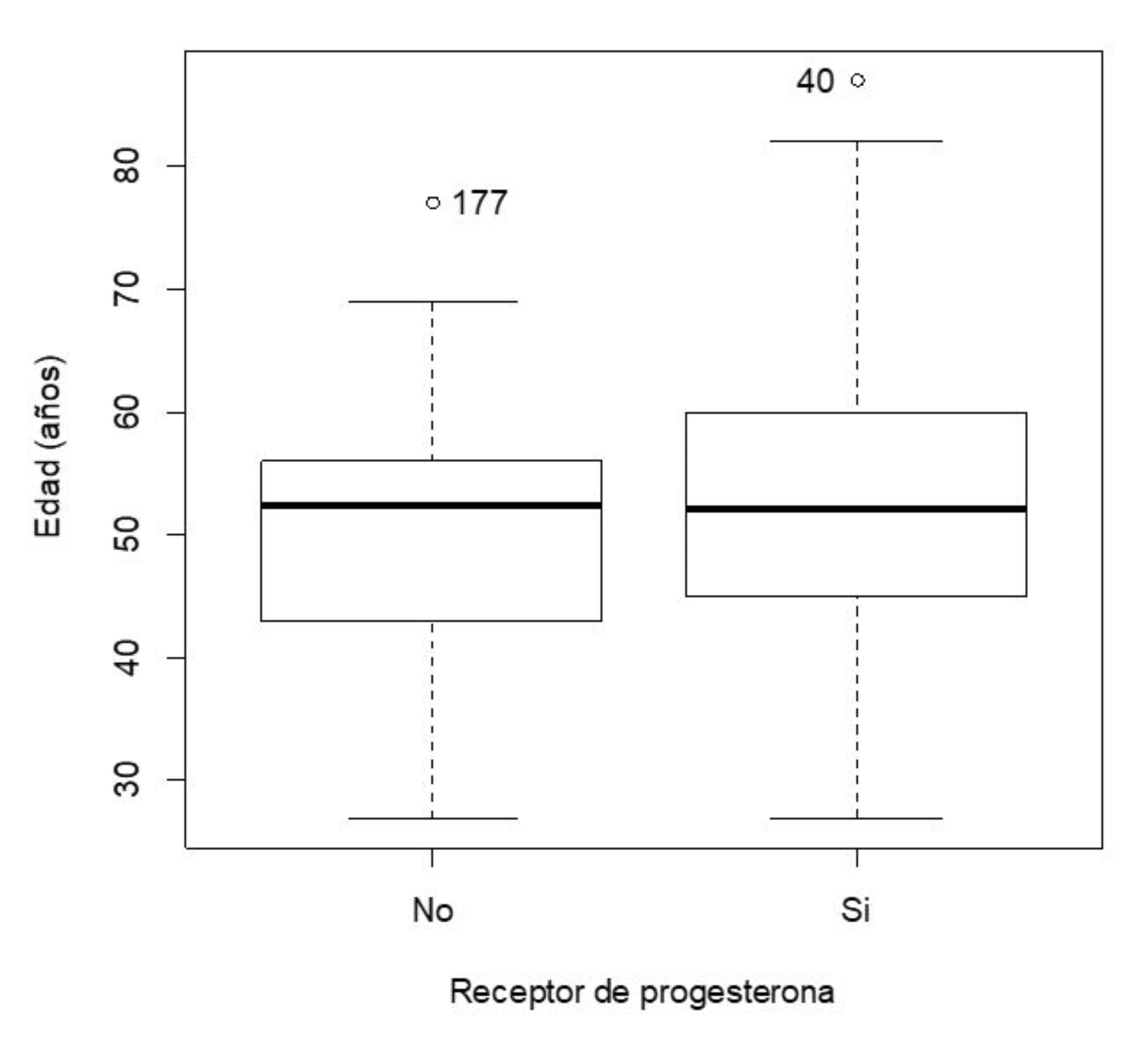
No me carga Restudio al hacer la instalacion. Es decir no funciona ninguna de las funciones del Menu,
¿ QUE SE PUEDE HACER EN TAL CASO?
AGRADECERIA AYUDA
Buenas tardes,
estoy intentando hacer un juego con R y la verdad es que me he quedado pillada en el siguiente problema:
una vez planteado un v1 y un v2, ambos van echando sus componentes v1[1], v2[1]; v1[2], v2[2]...etc. entonces con un if he puesto que si v1[i]>v2[i], v1 gana 2 puntos en esa tirada, viceversa y que si empatan hay que mirar las siguientes componentes v1[i+1] y v2[i+1] hasta desempatar y el que gane sumaría el doble de puntos (si hay 2 empates, el triple; si hay 3 empates, el cuádruple,..., etc.).
Mi cuestión es cómo hacer que el bucle siga si empatan (con esa misma condición) y cómo poner el contador 1 para el primer jugador y un segundo contador para el otro jugador.
Gracias de antemano y un saludo.
Buenos días, estoy haciendo un ejercicio con 60 tiendas… estoy intentando tener todo organizado en matrices pero la información que obtengo es en data.frame.
> str(test)
List of 2 $ Maria de Molina:'data.frame': 5 obs. of 2 variables:..$ date : Date[1:5], format: "2017-11-28" "2017-11-29" "2017-11-30" "2017-12-01" ...
..$ PX_LAST: num [1:5] 263 263 265 264 264 $ Tomas Morales:'data.frame': 5 obs. of 2 variables: ..$ date : Date[1:5], format: "2017-11-28" "2017-11-29" "2017-11-30" "2017-12-01" ... ..$ PX_LAST: num [1:5] 2626 2625 2648 2644 2638> test
$`Maria de Molina`
date PX_LAST1 2017-11-28 262.872 2017-11-29 262.713 2017-11-30 265.014 2017-12-01 264.465 2017-12-04 264.14 $`Tomas Morales` date PX_LAST1 2017-11-28 2626.00
2 2017-11-29 2625.00
3 2017-11-30 2648.00
4 2017-12-01 2644.00
5 2017-12-04 2638.25
Si hago un > write.csv(test,file = pathTiendas) el fichero que sale es de la siguiente manera:
Maria.de.Molina.date |
Maria.de.Molina.PX_LAST |
Tomas.Morales.date |
Tomas.Morales.PX_LAST |
|
1 |
11/28/2017 |
262.87 |
11/28/2017 |
2626 |
2 |
11/29/2017 |
262.71 |
11/29/2017 |
2625 |
3 |
11/30/2017 |
265.01 |
11/30/2017 |
2648 |
4 |
12/1/2017 |
264.46 |
12/1/2017 |
2644 |
5 |
12/4/2017 |
264.14 |
12/4/2017 |
2638.25 |
Me gustaría poder modificar la data.frame para que el resultado que salga en el csv fuera:
1 |
11/28/2017 |
Maria de Molina |
262.87 |
2 |
11/29/2017 |
Maria de Molina |
262.71 |
3 |
11/30/2017 |
Maria de Molina |
265.01 |
4 |
12/1/2017 |
Maria de Molina |
264.46 |
5 |
12/4/2017 |
Maria de Molina |
264.14 |
6 |
11/28/2017 |
Tomas Morales |
2626 |
7 |
11/29/2017 |
Tomas Morales |
2625 |
8 |
11/30/2017 |
Tomas Morales |
2648 |
9 |
12/1/2017 |
Tomas Morales |
2644 |
10 |
12/4/2017 |
Tomas Morales |
2638.25 |
Por favor, ¿Me podeis echar una mano?
Gracias.
Hola,
Tengo la siguiente distribución binomial:
> set.seed(625766839)
> dist<- rbinom(100,10,0.25)
[1] 2 0 4 1 4 2 3 1 2 2 3 3 1 1 3 0 3 4 3 1 3 3 4 2 3 4 2 2 3 5 4 1 2 3 3 2 3 4 1 2
[41] 5 2 2 7 2 2 2 7 5 1 0 2 1 3 0 1 4 1 1 4 3 3 3 3 2 3 2 2 2 2 4 2 1 4 4 0 5 2 4 3
[81] 1 1 6 3 1 0 3 2 1 1 4 2 5 1 2 1 1 3 4 3
Necesitaría dibujar un histograma con los valores generados para dist, y superponer la
la curva normal que se esperaría según el teorema
central del límite.El problema es que al tratarse de variables categóricas, lo que en realidad tendría que dibujar es un barplot y sobre el superponer la curva normal, que al tener diferente escala en el eje y, me queda muy pequeña, como se ve en la siguiente imagen:
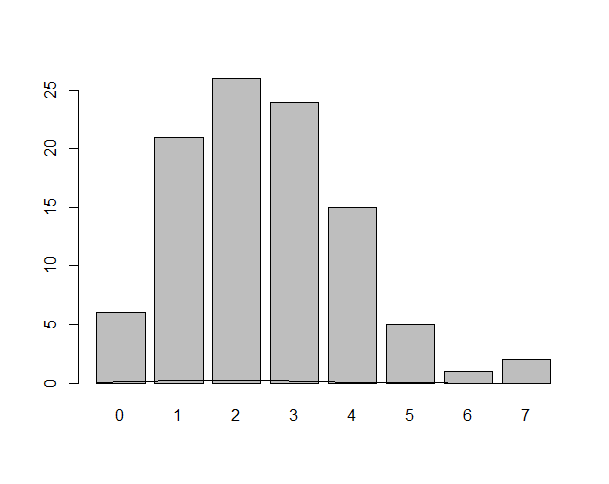
graf2<- curve(dnorm(x,2.5,1.37),-1,7)en el barplot de la figura de arriba, de forma que me quedara algo similar a esto:
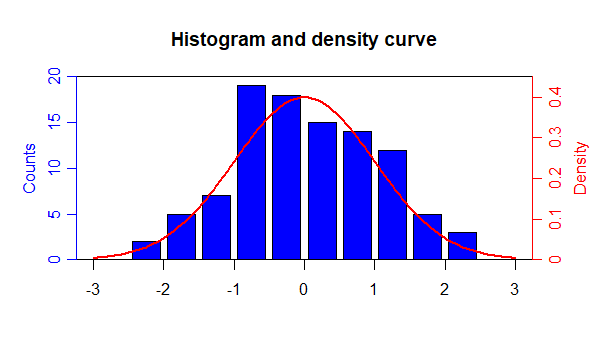
Gracias!!!